
LangGraph是构建复杂AI工作流的神器,其核心三要素为State(状态机)、Node(干活/函数)和Edge(流程控制)。它将复杂流程抽象为可维护的节点,每个节点可引入LLM或工具处理,使工作流清晰可控。作为图形处理引擎,通过compile和invoke执行,state作为共享数据结构在节点间传递更新,适合需要流程控制的应用场景。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
“「 嘿兄弟,我好想交女朋友但都交不到,怎么办? 」”
身为 AI 工程师,为了帮他,当然是画个流程图啊!
交女朋友要分步骤,每个步骤都有单一目的。 如果失败也没关系,流程上我们退回去反省一下,再接再厉
「… 这 TM? 一点都不实际 ”
有道理,一定是因为没有用 LangGraph 的关系!
用了 LangGraph 一切都实际了起来!
用 LangGraph 把每个步骤都接上 LLM 或者是 Tool(搜索), 要流程有流程,要行动有行动 ,这就是交友 agent 。
为什么要 LangGraph?
当你的产品需要一些流程、步骤,用 LangGraph 搭配 LangChain
- • 能够实现 workflow / Agent 搭建
- • 轻易把 LLM 引入每个步骤当中
- • 把流程抽象出来,好维护。 把每一个复杂的步骤封装起来。
可是,LangGraph 怎么做到呢? 有三个要素!
LangGraph 是什么?
LangGraph 三要素:
- •State: 状态机,如同变量表
- •Node: 干活 / 函数
- •Edge:流程控制
太抽象? 给个简单例子
# **State**class MyState(TypedDict): # from typing import TypedDict i: int j: int# Functions on **nodes**def fn1(state: MyState): print(f"Enter fn1: {state['i']}") return {"i": 1}def fn2(state: MyState): i = state["i"] return {"i": i+1}# Conditional **edge** functiondef is_big_enough(state: MyState): if state["i"] > 10: return END else: return "n2"# The Graph! The "Program" !!workflow = StateGraph(MyState)workflow.add_node("n1", fn1)workflow.add_node("n2", fn2)workflow.set_entry_point("n1")workflow.add_edge("n1", "n2")workflow.add_conditional_edges( source="n2", path=is_big_enough)# Compile, and then rungraph = workflow.compile()r = graph.invoke({"i": 1000, "j": 123})print(r) ```这个 graph 的可视化执行过程: 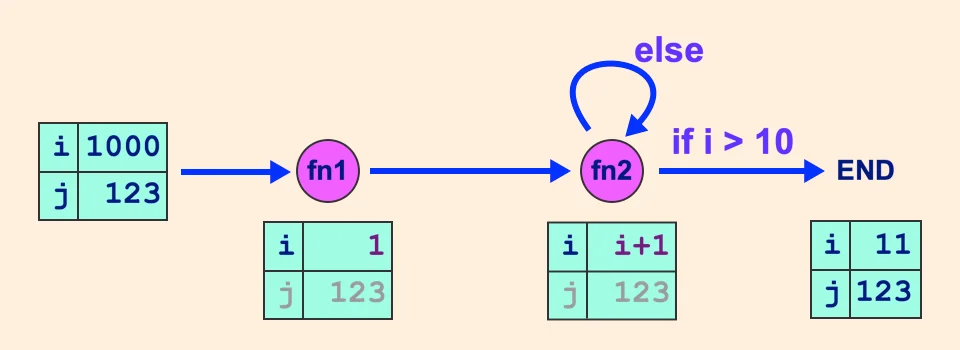 最后输出: ```plaintext {'i': 11, 'j': 123}跟单纯写 python 程序的不同,LangGraph 能够让每一个「步骤」都很复杂, 引入 LLM 跟工具的处理,把「流程」抽象出来 ,变得干净好维护。
Graph 像是一个子程序
在这个例子 MyState 其实是一个字典,先知道这样,后面有更多解释。
1. Node 节点
fn1 跟 fn2 两个 function,因为他们由 add_node() 绑在节点上 – 前面说了 Node 就是在干活,可以理解为具体的打工人。
何谓干活? 通常是「改变 state」,当然也可以是具体的某个事情,比如读取文件、写文件等。
def fn1(state: MyState): print(f"Enter fn1: {state['i']}") return {"i": 1}def fn2(state: MyState): i = state["i"] return {"i": i+1}- • 想象 state (状态) 是属于这个 graph 的「变量表」。
- •
fn1先打印传入的 state; 回传{“i”: 1}代表「不管 state 的 i 以前是多少,现在覆盖掉,变成 1 - • 同理,
fn2把 state 的 i 加上 1 以后回传,代表「state 里面的 i 多加 1
- • 注意
state[“i”]是这个 graph 里面的变数,在其他节点的 function 也能存取。
光是定义 function 不够,还要绑到 graph 上,给每个 node 一个名字:
workflow.add_node("n1", fn1)workflow.add_node("n2", fn2)2. Edge 边
执行顺序呢? 这就是 “edge” 控制了:从一个点有方向地连到另一个点
workflow.set_entry_point("n1")workflow.add_edge("n1", "n2")workflow.add_conditional_edges( source="n2", path=is_big_enough)- •
set_entry_point()指定从哪个 node 开始执行 - •
add_edge(“n1”, “n2”)表示当 n1 执行完以后,下一步就交给 n2 执行 - • 条件判断用
.add_conditional_edges()实现,等价于程序里的“if”。它需要至少两个参数
- • source 表示起点
- • path 是一个 function 决定下一步给谁:看他回传的字串代表哪个 node。
- • 示例代码中
is_big_enough这个函数,去看 state 变量表里的 i 有没有大于 10,没有的话就回传 “n2”,也就是下一棒再交给自己。 大于 10 的话就结束( END)
def is_big_enough(state: MyState): if state["i"] > 10: return END else: return "n2"所以整个 Graph 看起来像个子程序! 把 workflow 当作代码、state 当作变量表,compile 编译成执行文件:
graph = workflow.compile()r = graph.invoke({"i": 1000, "j": 123})print(r)- • 整个 graph 需要
.compile()才是一个能执行的 graph。 而 Compile 之后,后加的 node/edge 不会反映在上面 - •
.invoke()是输入初始的 state 去执行; 输出是最后的 state - • 虽然所有节点都没碰触 j – 也就是回传的都是 partial state ,但 state 的 schema 是 TypeDict, 里面有定义 j,所以如果初始有给 j 值,也会一直保留,最后的输出会有 j
Enter fn1: 1000{'i': 11, 'j': 123}对了,有没有发现: 示例代码完全没 AI 模型 。LangGraph 本质上就是个 “graph processing” engine 而已!
3. State 状态
State是一个共享的数据结构,在 graph 的节点之间传递和更新,在上面的代码中我们已经看到了,节点函数fn1、fn2可以读取 state 并进行修改
class MyState(TypedDict): i: int j: int...def fn2(state: MyState): i = state["i"] return {"i": i+1}核心特性
State就像是一个在图中流动的"数据包",每个节点都可以检查它、修改它,然后传递给下一个节点。这种设计让复杂的 AI 工作流变得清晰可维护。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段:从大模型系统设计入手,讲解大模型的主要方法;
第二阶段:在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段:大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段:大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段:大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段:以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段:以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求:大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能,学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力:大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓





